Second brain
A Self-Improving Company of One
Tom Blomfield's YC talk pitches a company that catalogues everything to improve itself. I run a smaller version of the loop as a second brain on Obsidian and Claude.
I was watching Tom Blomfield’s YC talk on building an AI-first company when one idea caught me: catalogue everything that happens inside a company, from meeting transcripts to decisions, and feed that record back to improve how the company runs.
I am not running a company, but I have been running a smaller version of that loop on Obsidian and Claude for a few months. The talk did not teach me the habit; it named one I already had, which is the only reason I trust it enough to write it down.
A Logbook and Two Commands
The idea is not new. It got popular through Karpathy’s LLM wiki, and a wave of Obsidian-plus-Claude videos turned it into its own genre. The shape is always the same: a pile of markdown files, organised into folders and skills so a model can rebuild context in seconds.
My repository was already tidy. The thing that kept failing was memory. The same friction came back across sessions: a tool the model used wrong, a path it guessed instead of reading. Those were exactly the cases that should have become a rule, and in the moment I almost never remembered to write them down.
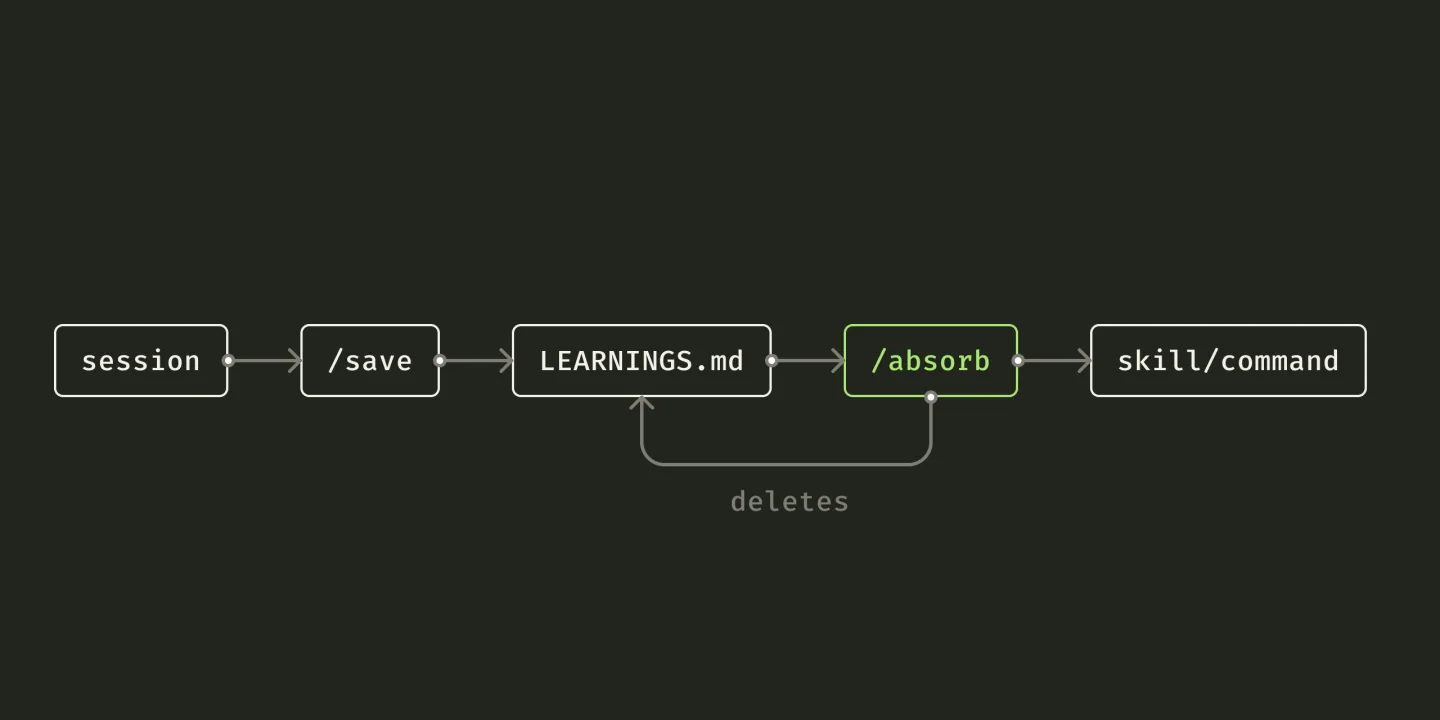
So I wired the habit into the one point where I already stop and think, the end of a session. When I close one out with /save, the command reviews what changed, organises the commits, and appends anything I learned to a file called LEARNINGS.md. It reads like a logbook of small corrections.
## 2026-06-11
- Agent rewrote a file I never named. Confirm the target path before any write.
- Sub-agents drop pt-BR diacritics. Pin "use á, ã, ç, é" in the prompt.On its own, a logbook just grows. The second command, /absorb, is the one that earns its keep: every week or so it reads LEARNINGS.md, decides which entries deserve promotion into a permanent skill or command, makes the edit, and deletes the ones it absorbed so the file does not rot into a graveyard. Capture is cheap. The promotion step is where the system actually learns. I did not invent any of this; I just gave two boring commands a standing appointment.
The same instinct shows up elsewhere. When I start something new, /projects/new asks me a handful of questions and scaffolds the folders I would have built by hand anyway, the same way every time. Consistency stops being something I maintain and becomes something the command remembers.
Where I Get Off the Train
This is where I step off the AI-first script a little. The usual pitch is to capture everything and let the agents sort it out, total recall sold as a feature. I do the opposite on the part that matters: the capture is automatic, but the decision about what becomes a rule is not. /absorb proposes, and I still read the diff before a learning hardens into a skill that will shape every future session.
I get off there because promoting a learning into a skill is closer to writing policy than taking a note. From then on it shapes every session, so a wrong entry biases everything the model does next. A note you can ignore. A skill you cannot. I would rather keep the logbook a little messy and keep the promotion deliberate: the machine keeps the record, I keep the editorial call.
Meetings and Money
Scaled up, it is almost the same drawing. Picture meeting transcripts landing automatically in a shared Drive folder. A webhook fires on each new file, and an agent reads the transcript the way /save reads a session: it pulls out the decisions, names who owns each action, flags the blockers nobody said out loud, and files the summary next to the product it belongs to. The next person who asks “what did we decide about pricing?” gets an answer that already exists instead of scrubbing through a recording.
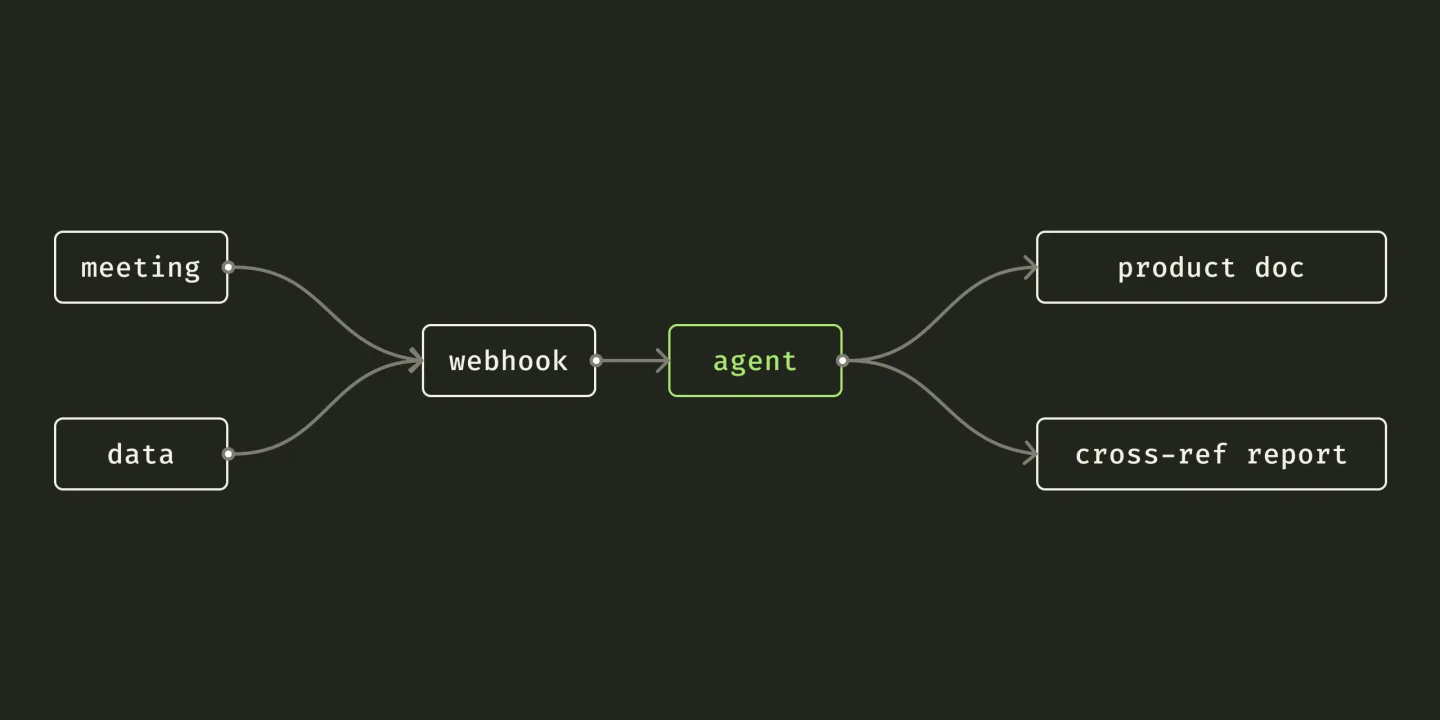
Data is the other half. Once the same context holds the sales numbers, the site traffic, and the churn it would rather not look at, an agent can write the weekly report and, more usefully, cross the streams: this dip in repeat orders lines up with the launch we argued about on the 12th. That is the part that got me. Finding where the money leaks stops being an out-of-this-world project you hire a consultancy for and turns into another task on an ordinary Tuesday. You cannot improve a funnel you only feel. You can improve one you can read.
The Weak Link
I should be honest about the soft spot. None of this works if the capture is bad. A transcript that misses who said what, a learning written too vaguely to act on, and the loop cheerfully promotes a bad rule and repeats it with confidence. The system is only as good as the worst thing it writes down, and right now the weak link is still me, remembering to feed it.
If you want the unglamorous version of how the personal setup is built, I wrote it up in the second brain case study. The open question I keep circling is where the line sits: how much of the editorial call can I hand to the machine before the record starts shaping me more than I shape it?